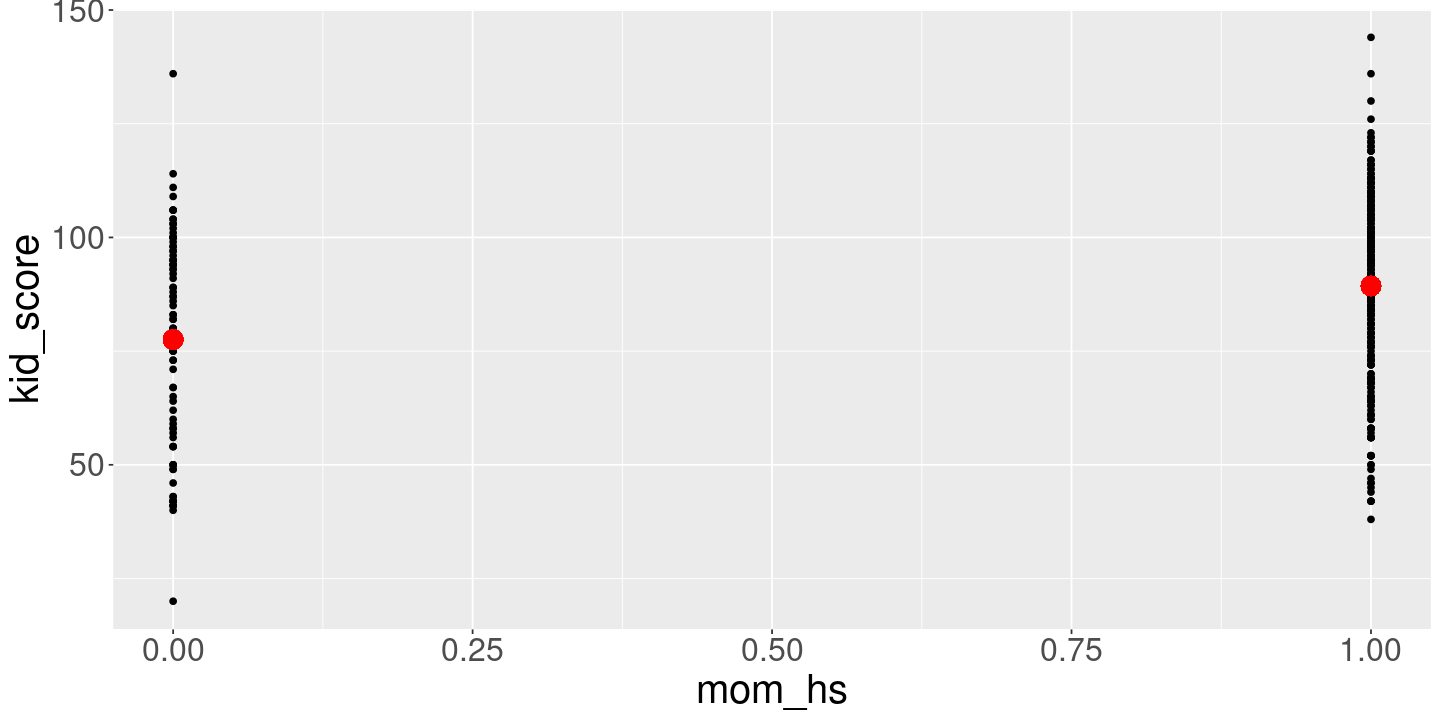
Let’s regress the kid’s IQ score on a constant and on whether or not the mom went to high school. This should be interepreted as a comparison between groups, not the effect of “going to high school.”
# There are many ways to get estimates out of lm.print(summary(fit1))cat("\n----------------\n")print(summary(fit1)$coefficients)cat("\n----------------\n")print(coefficients(fit1))
Call:
lm(formula = kid_score ~ mom_hs, data = kidiq)
Residuals:
Min 1Q Median 3Q Max
-57.55 -13.32 2.68 14.68 58.45
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 77.548 2.059 37.670 < 2e-16 ***
mom_hs 11.771 2.322 5.069 5.96e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 19.85 on 432 degrees of freedom
Multiple R-squared: 0.05613, Adjusted R-squared: 0.05394
F-statistic: 25.69 on 1 and 432 DF, p-value: 5.957e-07
----------------
Estimate Std. Error t value Pr(>|t|)
(Intercept) 77.54839 2.058612 37.670231 1.392224e-138
mom_hs 11.77126 2.322427 5.068516 5.956524e-07
----------------
(Intercept) mom_hs
77.54839 11.77126
We can interpret the coefficients as the means within samples. Arguably the easiest way to see this is to re-write our regressors. The problem uses \(x_n^\trans = (1, i_n)\) where \(i_n\) is \(1\) if the mom went to high school and \(0\) otherwise. It is somewhat easier to see what the coefficients are estimating if you write the regression in the form of the transformed variable
where \(N_0\) and \(N_1\) are the respective counts of rows of moms without and with high school education. From this it follows that, regressing \(\y_n \sim \zv_n^\trans \gamma\), that
the means of the response within the two groups. Using the fact that \(\zv_n\) is an invertible transformation of \(\xv_n\), and so the least squares fit is the same at each possible regressor value, we get
So the least square estimates are just comparing means within groups in this case.
Exercise
Prove that, if \(\xv_n\) takes one of \(P\) distinct values, then \(\betahat\) is always a linear combination of the sample means of the response within observations taking the distinct values. Find the linear combination, and prove the present result as a special case.
Let’s go through and confirm that lm is calculating exactly the same quantites we’ve been looking at in class.
Check that the coefficient estimates are given by \(\betavhat = (\X^\trans \X)^{-1} \X^\trans \Y\).
xmat <-model.matrix(fit1)yvec <- kidiq$kid_scorextx <-t(xmat) %*% xmatbetahat <-solve(xtx, t(xmat) %*% yvec)cat("\nThe betahat is the same in lm:\n")print(cbind(betahat, coefficients(fit1)))
The betahat is the same in lm:
[,1] [,2]
(Intercept) 77.54839 77.54839
mom_hs 11.77126 11.77126
Check that the residuals are given by \(\Y - \X \betavhat\).
reshat <- yvec - xmat %*% betahatcat("\nThe estimated residuals are the same in lm:\n")print(max(abs(reshat - fit1$residuals)))
The estimated residuals are the same in lm:
[1] 4.902745e-13
The residual estimated variances is given by \(\sigmahat^2 = \frac{1}{N - P} \sumn \reshat_n\).
sigmahat2 <-sum(reshat^2) / (nrow(xmat) -ncol(xmat))cat("\nThe residual variance estimates are the same in lm:\n")print(sigmahat2)print(sigma(fit1)^2)
The residual variance estimates are the same in lm:
[1] 394.1231
[1] 394.1231
The estimated covariance \(\cov{\betahat - \beta}\) is given by \(\sigmahat^2 (\X^\trans\X)^{-1}\), the homoskedastic covariance estimate.
betahat_cov <- sigmahat2 *solve(xtx)cat("\nThe betahat covariance are the same in lm:\n")print(betahat_cov)print(vcov(fit1))
The betahat covariance are the same in lm:
(Intercept) mom_hs
(Intercept) 4.237883 -4.237883
mom_hs -4.237883 5.393669
(Intercept) mom_hs
(Intercept) 4.237883 -4.237883
mom_hs -4.237883 5.393669
The sandwich covariance matrix can also be used, though it’s not the default for lm. Note that the sandwich package has lots of variants, read the documentation for more information.
The reported “standard errors” are the square root of the diagonal of the covariance matrix.
cat("\nThe betahat standard errors are the same in lm:\n")betahat_sd <-sqrt(diag(betahat_cov))print(cbind(betahat_sd, summary(fit1)$coefficients[,"Std. Error"]))
The betahat standard errors are the same in lm:
betahat_sd
(Intercept) 2.058612 2.058612
mom_hs 2.322427 2.322427
Recall that, if \(\betahat_k - \beta_k \sim \gauss{0, \sigma^2 v_k}\), then we have shown that, under the normal assumption,
Here \(\sigmahat v_k\) would just be the “standard error” from above, that is, the square root of the \(k\)–th entry of the diagonal of the estimated covariance matrix.
alpha =0.05zalpha <--1*qt(alpha /2, df=nrow(xmat) -ncol(xmat))ci <- betahat[2] + betahat_sd[2] *c(-zalpha, zalpha)cat("\nThe confidence values are the same as lm:\n")print(ci)print(confint(fit1, "mom_hs", level=1- alpha))
The confidence values are the same as lm:
[1] 7.206598 16.335924
2.5 % 97.5 %
mom_hs 7.206598 16.33592
The t-values and p-values are about hypothesis tests for the hypothesis that \(\betav = 0\) using the student-t distribution.
First, the t-values is the statistic \(t_k\) defined above for \(\beta_k = 0\). This is how far away from zero the t-statistic would have to be had \(\beta_k\) been equal to \(0\).
The p-value is then the \(\alpha\) for which you would have included \(0\) in your confidence interval. Equivalently, it is the probability of observing \(t_k\) as large or larger than what you actually observed, had \(\beta_k\) actually been equal to zero.
cat("\nThe t values are the same in lm:\n")t_value <- betahat / betahat_sdprint(cbind(t_value, summary(fit1)$coefficients[, "t value"]))cat("\nThe p values are the same in lm:\n")df <-nrow(xmat) -ncol(xmat)p_value <-pt(-abs(t_value), df=df) *2print(cbind(p_value, summary(fit1)$coefficients[, "Pr(>|t|)"]))
The t values are the same in lm:
[,1] [,2]
(Intercept) 37.670231 37.670231
mom_hs 5.068516 5.068516
The p values are the same in lm:
[,1] [,2]
(Intercept) 1.392224e-138 1.392224e-138
mom_hs 5.956524e-07 5.956524e-07
We can check that the F-statistic matches as well.
summary(fit1)
Call:
lm(formula = kid_score ~ mom_hs, data = kidiq)
Residuals:
Min 1Q Median 3Q Max
-57.55 -13.32 2.68 14.68 58.45
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 77.548 2.059 37.670 < 2e-16 ***
mom_hs 11.771 2.322 5.069 5.96e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 19.85 on 432 degrees of freedom
Multiple R-squared: 0.05613, Adjusted R-squared: 0.05394
F-statistic: 25.69 on 1 and 432 DF, p-value: 5.957e-07
Call:
lm(formula = kid_score ~ mom_hs, data = kidiq)
Residuals:
Min 1Q Median 3Q Max
-57.55 -13.32 2.68 14.68 58.45
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 77.548 2.059 37.670 < 2e-16 ***
mom_hs 11.771 2.322 5.069 5.96e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 19.85 on 432 degrees of freedom
Multiple R-squared: 0.05613, Adjusted R-squared: 0.05394
F-statistic: 25.69 on 1 and 432 DF, p-value: 5.957e-07
value numdf dendf
25.68986 1.00000 432.00000
non_intercept_rows <-names(coefficients(fit1)) !="(Intercept)"betahat_ni_cov <- betahat_cov[non_intercept_rows, non_intercept_rows, drop=FALSE]betahat_ni <-coefficients(fit1)[non_intercept_rows, drop=FALSE]f_stat_df <-sum(non_intercept_rows)f_stat_df2 <-length(fit1$fitted.values) -length(coefficients(fit1))f_stat <-t(betahat_ni) %*%solve(betahat_ni_cov, betahat_ni) / f_stat_dfcat("\nThe f statistic is same in lm:\n")print(cbind(f_stat, f_stats["value"]))cat("\nThe df statistic is same in lm:\n")print(cbind(f_stat_df, f_stats["numdf"]))print(cbind(f_stat_df2, f_stats["dendf"]))cat("\nThe f test p value is same in lm:\n")1-pf(f_stat, f_stat_df, f_stat_df2)cat("(Note that the summary() p-value is apparently computed in the print statement and not accessible directly)")#print(cbind(qf(f_stat, f_stat_df, f_stats["numdf"]))
The f statistic is same in lm:
[,1] [,2]
value 25.68986 25.68986
The df statistic is same in lm:
f_stat_df
numdf 1 1
f_stat_df2
dendf 432 432
The f test p value is same in lm:
(Note that the summary() p-value is apparently computed in the print statement and not accessible directly)