── Attaching core tidyverse packages ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.2 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
# fage: Father's age in years.# mage: Mother's age in years.# mature: Maturity status of mother.# weeks: Length of pregnancy in weeks.# premie: Whether the birth was classified as premature (premie) or full-term.# visits: Number of hospital visits during pregnancy.# gained: Weight gained by mother during pregnancy in pounds.# weight: Weight of the baby at birth in pounds.# lowbirthweight: Whether baby was classified as low birthweight (low) or not (not low).# sex: Sex of the baby, female or male.# habit: Status of the mother as a nonsmoker or a smoker.# marital: Whether mother is married or not married at birth.# whitemom: Whether mom is white or not white.df_raw <-read.csv("../datasets/births14.csv")
# Drop missing datadf_raw %>%summarise_all(~sum(is.na(.)))df <- df_raw %>%drop_na(everything())cat("Dropped ", nrow(df_raw) -nrow(df), " rows \n")print(nrow(df))head(df)# Meaning of truncated variablesdf %>%group_by(mature) %>%summarize(min(mage), max(mage))df %>%group_by(premie) %>%summarize(min(weeks), max(weeks))df %>%group_by(lowbirthweight) %>%summarize(min(weight), max(weight))
A data.frame: 1 × 13
fage
mage
mature
weeks
premie
visits
gained
weight
lowbirthweight
sex
habit
marital
whitemom
<int>
<int>
<int>
<int>
<int>
<int>
<int>
<int>
<int>
<int>
<int>
<int>
<int>
114
0
0
0
0
56
42
0
0
0
19
0
0
Dropped 206 rows
[1] 794
A data.frame: 6 × 13
fage
mage
mature
weeks
premie
visits
gained
weight
lowbirthweight
sex
habit
marital
whitemom
<int>
<int>
<chr>
<int>
<chr>
<int>
<int>
<dbl>
<chr>
<chr>
<chr>
<chr>
<chr>
1
34
34
younger mom
37
full term
14
28
6.96
not low
male
nonsmoker
married
white
2
36
31
younger mom
41
full term
12
41
8.86
not low
female
nonsmoker
married
white
3
37
36
mature mom
37
full term
10
28
7.51
not low
female
nonsmoker
married
not white
4
32
31
younger mom
36
premie
12
48
6.75
not low
female
nonsmoker
married
white
5
32
26
younger mom
39
full term
14
45
6.69
not low
female
nonsmoker
married
white
6
37
36
mature mom
36
premie
10
20
6.13
not low
female
nonsmoker
married
white
A tibble: 2 × 3
mature
min(mage)
max(mage)
<chr>
<int>
<int>
mature mom
35
47
younger mom
14
34
A tibble: 2 × 3
premie
min(weeks)
max(weeks)
<chr>
<int>
<int>
full term
37
46
premie
23
36
A tibble: 2 × 3
lowbirthweight
min(weight)
max(weight)
<chr>
<dbl>
<dbl>
low
1.12
5.50
not low
5.50
10.42
y_col <-"weight"# We don't want to deal with collinear regressors in small samplesx_cols <-c("mage", "fage", "sex")reg_form <-sprintf("%s ~ 1 + %s", y_col, paste(x_cols, collapse=" + "))x_all <-model.matrix(formula(reg_form), df)y_all <- df[[y_col]]n_all <-length(y_all)stopifnot(nrow(x_all) == n_all)
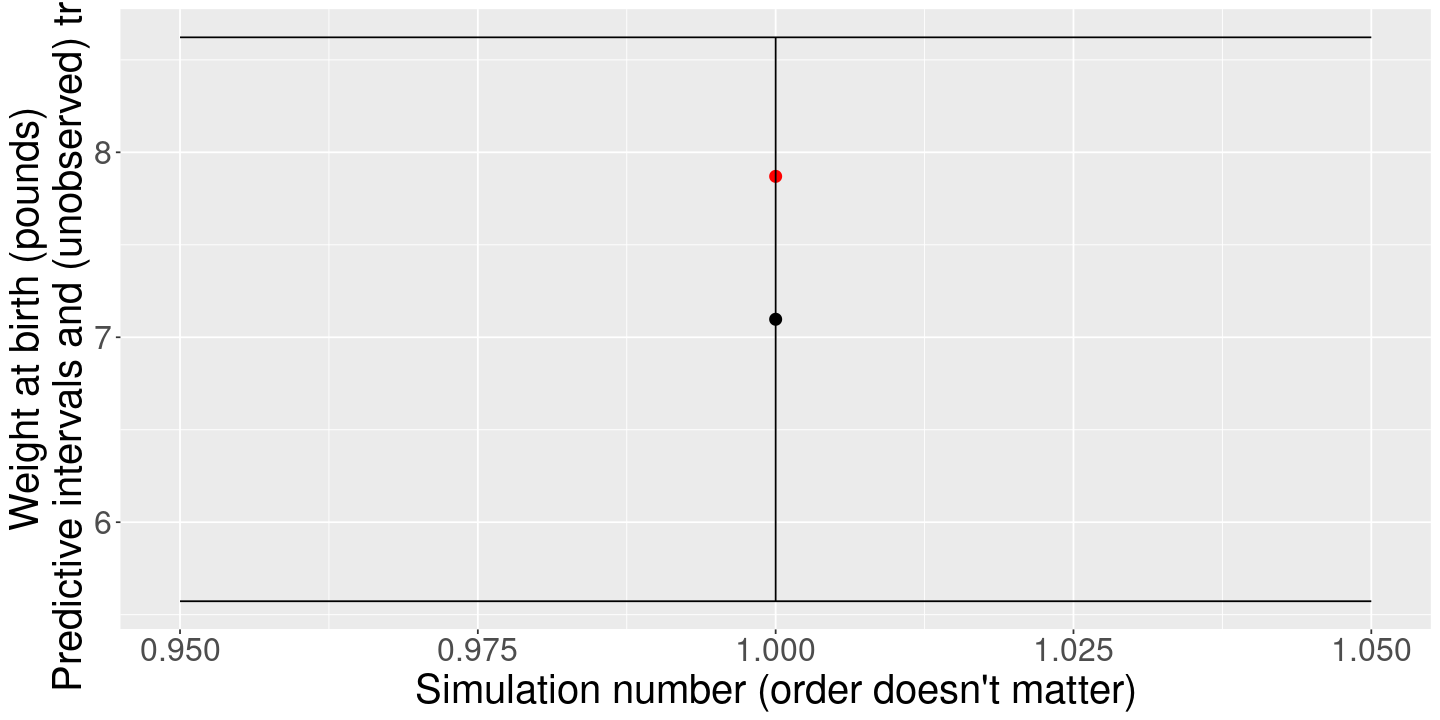
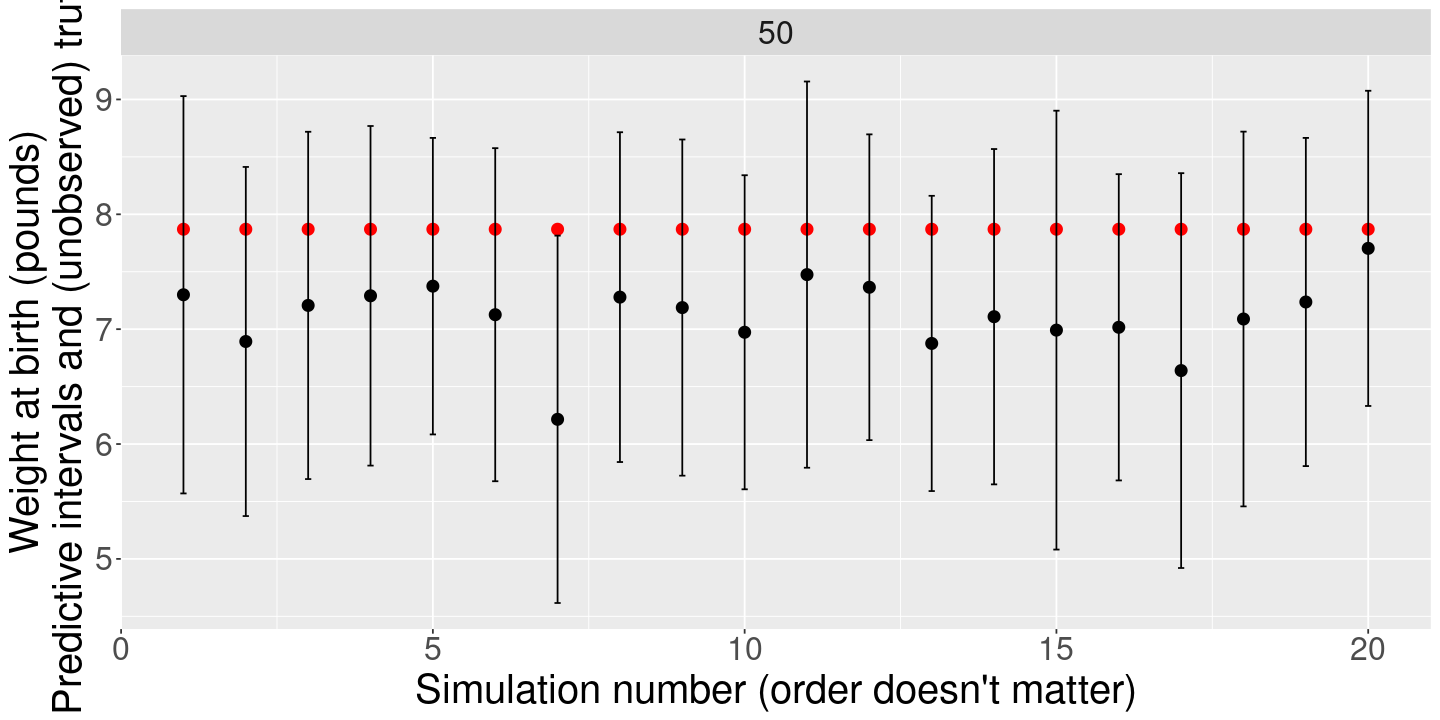
# Let's look at a single test pointtest_ind <-sample(n_all, 1) # Choose a single test pointx_test <- x_all[test_ind, ]y_test <- y_all[test_ind]print(x_test)print(y_test)
(Intercept) mage fage sexmale
1 30 27 0
[1] 7.87
# Sanity check that lm() is doing what we expectn_obs <-500train_inds <-sample(setdiff(1:n_all, test_ind), n_obs, replace=FALSE)x <- x_all[train_inds, ]y <- y_all[train_inds]print(dim(x))
[1] 500 4
print(reg_form)reg_fit <-lm(formula(reg_form), df[train_inds, ])betahat <-solve(t(x) %*% x, t(x) %*% y)bind_cols(coefficients(reg_fit), betahat)res <- y - x %*% betahatmax(abs(res -summary(reg_fit)$residual))sigmasqhat <-sum((y - x %*% betahat)^2) / (nrow(x) -ncol(x))c(sigmasqhat, summary(reg_fit)$sigma^2)