── Attaching core tidyverse packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.2 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Scalar-valued random variables
Here’s an example of the kind of thing we’ll do today. We’ll begin by looking at the LLN for standard normal random variables. Then, you’ll modify this code to explore other aspects of the LLN.
# This is the key function to modify. The rest is boilerplate (meaning code that is pretty much the# same every time you use it).# Draw a random sample mean.## Inputs:# - n_obs: The number of independent observations that form the sample mean# - true_mean: The true mean of the draws.# Returns:# A dataframe with three columns and one row:# - n: The number of samples that contributed to the sample mean# - value: The calculated sample mean# - quantity: A readable description of the random variableDrawLLNSample <-function(n_obs, true_mean) { x <-rnorm(n_obs, mean=true_mean) # <- We'll be modifying this linereturn(data.frame(n=n_obs, value=sum(x) / n_obs, quantity="normal"))}DrawLLNSample(40, 6)
A data.frame: 1 × 3
n
value
quantity
<dbl>
<dbl>
<chr>
40
5.969966
normal
# Draw a random sample mean.## Inputs:# - DrawFun: A function taking a single argument, the number of draws, and returning a dataframe# with the sample mean and other metadata# - n_obs_vec: A numeric vector containing the number of observations to tru# - num_draws: The number of independent draws to compute for each n_obs# Returns:# A dataframe with the output of DrawFun, and a column indicating which draw# index produced that dataframe.ConductLLNExperiment <-function(DrawFun, n_obs_vec=seq(10, 3000, by=30), num_draws=20) {# The rest of this can be mostly the same every time you run a univariate analysis lln_df <-data.frame() pb <-txtProgressBar(min=0, max=max(n_obs_vec), initial=0, style=3)for (n_obs in n_obs_vec) {setTxtProgressBar(pb, n_obs)for (draw in1:num_draws) { lln_df <-bind_rows( lln_df,DrawFun(n_obs) %>%mutate(draw=draw)) } }close(pb)return(lln_df)}
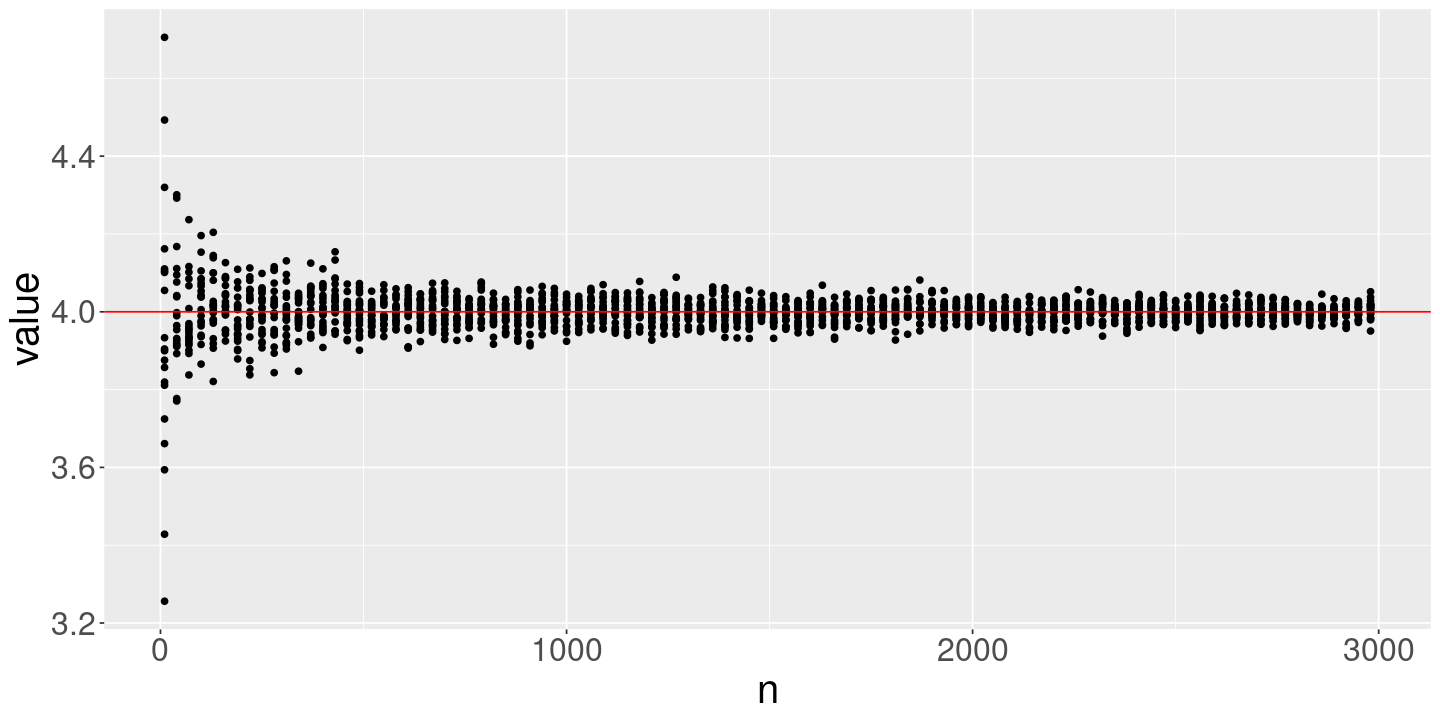
# Evaluate the sample average for these numbers of observationstrue_mean <-4DrawFun <-function(n_obs) {DrawLLNSample(n_obs, true_mean=true_mean)}lln_df <-ConductLLNExperiment(DrawFun)head(lln_df)
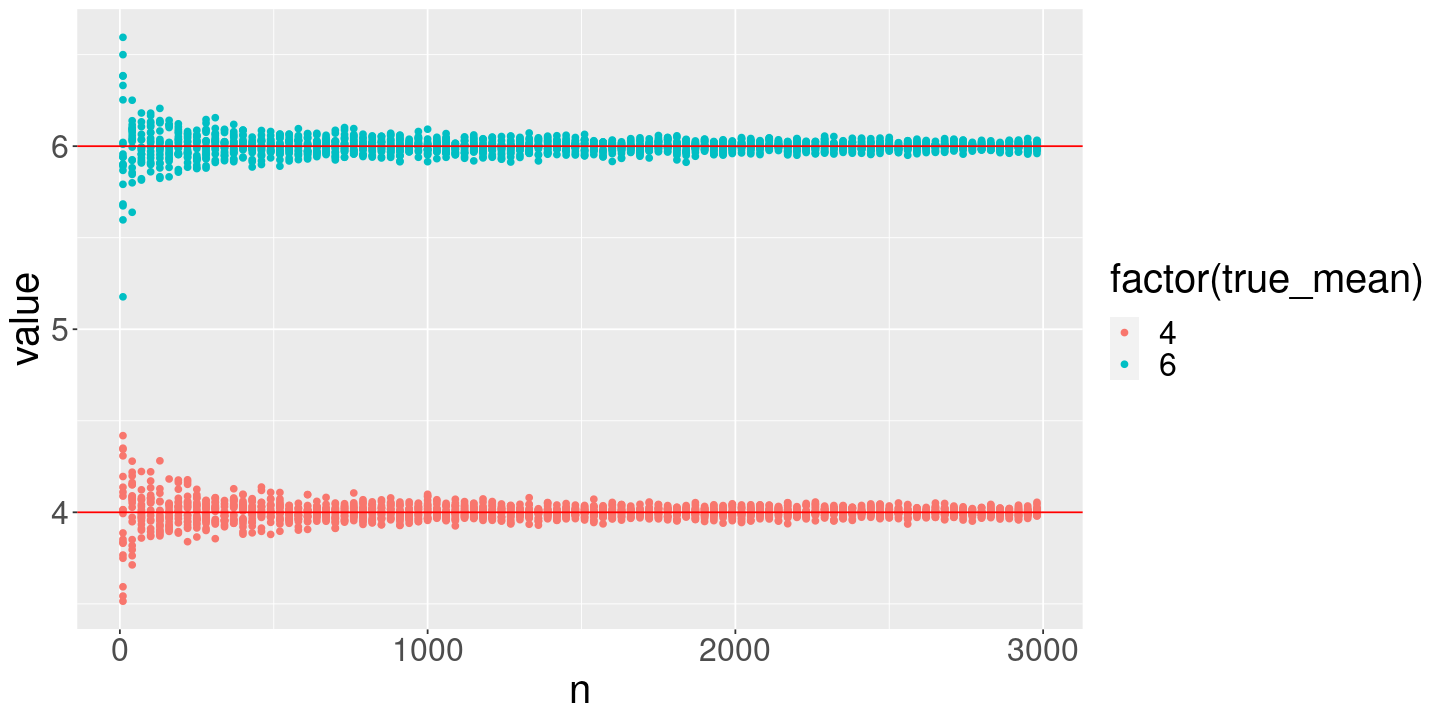
# A good way to compare different settings is to save them in the same dataframe# but with a descriptive column telling them apartlln_df <-data.frame()DrawFun <-function(n_obs) {DrawLLNSample(n_obs, true_mean=true_mean)}for (true_mean inc(4, 6)) { lln_df <-bind_rows( lln_df,ConductLLNExperiment(DrawFun) %>%mutate(true_mean=true_mean) )}ggplot(lln_df) +geom_point(aes(x=n, y=value, color=factor(true_mean)), alpha=1.0) +geom_hline(aes(yintercept=true_mean), color="red")
How does the variance of the draws affect the convergence?
How does the choice of distribution affect the convergence? Some options to try: rt, rcauchy, rgamma, runif.
How do transformations affect convergence? Some to try: \(f(x) = x^2\), \(f(x) = 1 / x\), \(f(x) = log(x)\), \(f(x) = e^x\).
Can you find a random variable so that the LLN does very badly when estimating \(1 / \overline{x}\)?
What does the plot of \(\sqrt{N} \overline{x}\) look like? How about \(N \overline{x}\)? Explain your answers.
Starting from, say, \(N = 100\), how many observations do you need to cut the typical error in half?
Vector-valued random variables
It will be useful to have these helper functions in order to convert draws of matrix and vector-valued random variables into tidy dataframes. Take a moment and make sure you understand what they do.
# Convert a matrix to a tidy dataframe.## Inputs:# - mat: A (possibly non-square) matrix# - prefix: A readable name describing the matrix# Returns:# - A dataframe with three columns:# value: The value of the matrix entry at <row>, <col># component: A column containing the location <prefix>.<row>.<col> # quantity: The value of <prefix> FlattenMatrix <-function(mat, prefix) { df_list <-list()if (!is.matrix(mat)) { mat <-as.matrix(mat) }for (d1 in1:nrow(mat)) {for (d2 in1:ncol(mat)) { df_list[[(paste0(prefix, ".", d1, ".", d2))]] <- mat[d1, d2, drop=FALSE] } }return(as.data.frame(df_list) %>%pivot_longer(cols=everything(), names_to="component") %>%mutate(quantity=prefix))}foo_mat <-matrix(1:6, nrow=3, ncol=2)print(FlattenMatrix(foo_mat, "foo"))print(foo_mat)foo_vec <-1:3print(FlattenMatrix(foo_vec, "foo"))print(foo_vec)
# Invert a matrix. If the matrix is singular, return a matrix# of NA, the same shape as the input, without terminating or raising an error.SafeSolve <-function(mat) { mat_inv <-matrix(NA, nrow(mat), ncol(mat) )tryCatch(mat_inv <-solve(mat),error=function(e) { })return(mat_inv)}print(SafeSolve(diag(3)))print(SafeSolve(matrix(0, 3, 3)))
[,1] [,2] [,3]
[1,] 1 0 0
[2,] 0 1 0
[3,] 0 0 1
[,1] [,2] [,3]
[1,] NA NA NA
[2,] NA NA NA
[3,] NA NA NA
We can now do the much the same thing for vectors that we did for scalars.
# Draw a random sample mean.# Inputs:# - n_obs: The number of independent observations that form the sample mean# - true_mean: The true mean of the draws.# Returns:# A dataframe with three columns and one row:# - n: The number of samples that contributed to the sample mean# - value: The calculated sample mean# - quantity: A readable description of the random variableDrawLLNVectorSample <-function(n_obs, true_mean, cov_mat) {stopifnot(ncol(cov_mat) ==nrow(cov_mat))stopifnot(length(true_mean) ==nrow(cov_mat)) x <-rmvnorm(n_obs, mean=true_mean, sigma=cov_mat) xbar <-apply(x, FUN=sum, MARGIN=2) / n_obsreturn(FlattenMatrix(xbar, "xbar") %>%mutate(n=n_obs, quantity="xbar"))}
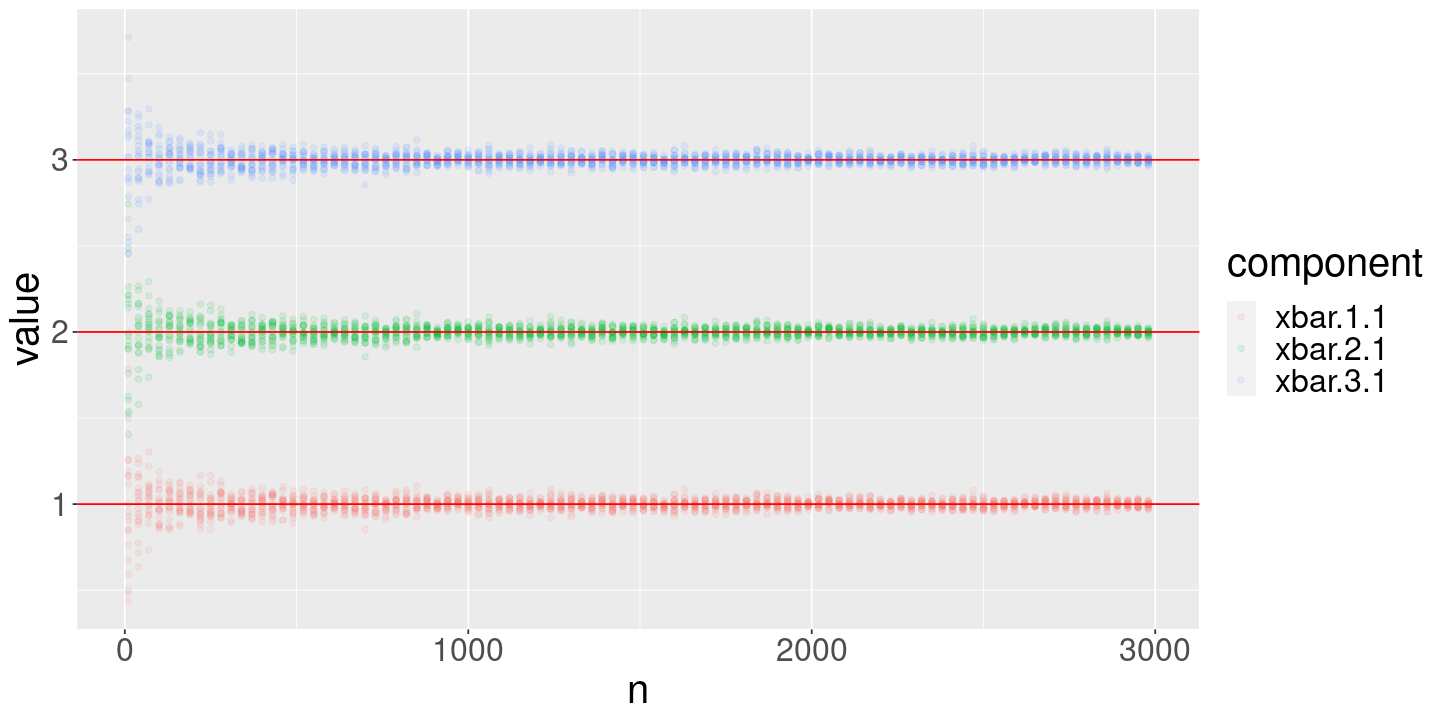
# Set some parameters and sanity check the outputx_dim <-3true_mean <-1:x_dim#cov_mat <- diag(x_dim)cov_mat <-matrix(0.99, x_dim, x_dim)diag(cov_mat) <-1print(cov_mat)DrawLLNVectorSample(10, true_mean, cov_mat)
# Evaluate the sample average for these numbers of observationsDrawFun <-function(n_obs) {DrawLLNVectorSample(n_obs, true_mean=true_mean, cov_mat=cov_mat)}lln_df <-ConductLLNExperiment(DrawFun)ggplot(lln_df) +geom_point(aes(x=n, y=value, color=component), alpha=0.1) +geom_hline(aes(yintercept=value), color="red",data=FlattenMatrix(true_mean, "xbar"))
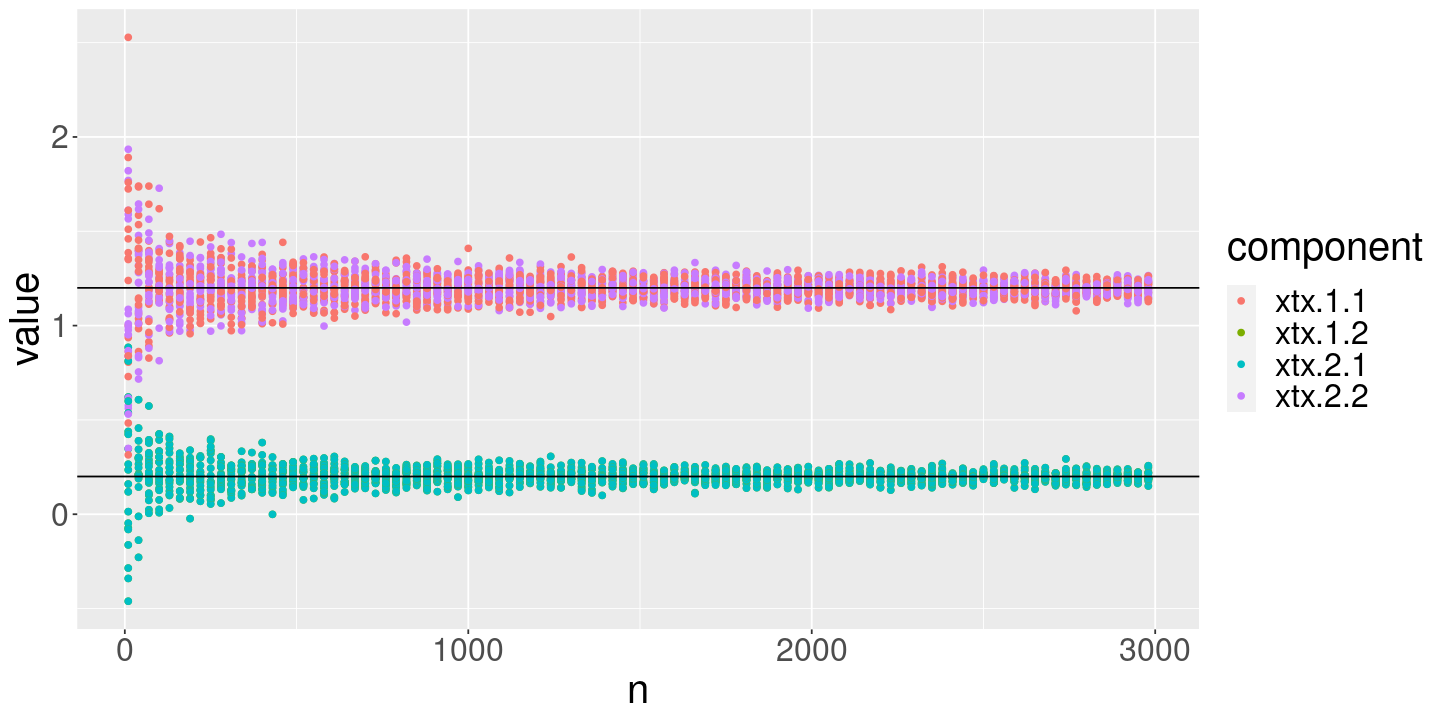
xtx_limit <-FlattenMatrix(x_cov, prefix="xtx")# Evaluate the sample average for these numbers of observationsDrawFun <-function(n_obs) {DrawRegressionResult(n_obs, x_cov=x_cov, beta_true=beta_true, sigma_true=sigma_true)}lln_df <-ConductLLNExperiment(DrawFun)ggplot(lln_df) +geom_point(aes(x=n, y=value, color=component, group=interaction(draw, component))) +geom_hline(aes(yintercept=value), data=xtx_limit)