── Attaching core tidyverse packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.2 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.2 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.1
── Conflicts ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Attaching package: ‘gridExtra’
The following object is masked from ‘package:dplyr’:
combine
# Create a feature matrix at the grid points x in [0,1] using pmax# sinusoidal Fourier featuresEvalFeatures <-function(x, pmax) { n_obs <-length(x) freqs <-rep(pi * (1:pmax), each=n_obs) f_mat <-matrix(sin(freqs *rep(x, pmax)), nrow=n_obs, ncol=pmax)colnames(f_mat) <-paste0("f", 1:pmax)return(f_mat)}# Draw a regression dataset with# - n_obs: number of observations# - sigma_true: residual standard deviation# - beta_true: regression coefficient# - x: A set of x in [0,1] at which to evaluate the features, or a uniform draw if nullDrawData <-function(n_obs, sigma_true, beta_true, x=NULL) {if (is.null(x)) { x <-runif(n_obs) } f_mat <-EvalFeatures(x, length(beta_true)) ey_true <- f_mat %*% beta_true y <- ey_true +rnorm(n_obs, sd=sigma_true) data_df <-data.frame(f_mat) %>%mutate(x=x, y=y, ey_true=ey_true) %>%mutate(n=1:n())return(data_df)}# Select a beta with decaying content at higher frequencies,# but with only the first p_true components non-zero GetBeta <-function(p_true) { beta_full <- (runif(pmax) +0.1) / (1:pmax) beta_full <- beta_full /sqrt(sum(beta_full^2)) beta_true <-rep(0, pmax) beta_true[1:p_true] <- beta_full[1:p_true]return(beta_true)}
Simulated example: A sinusoidal basis
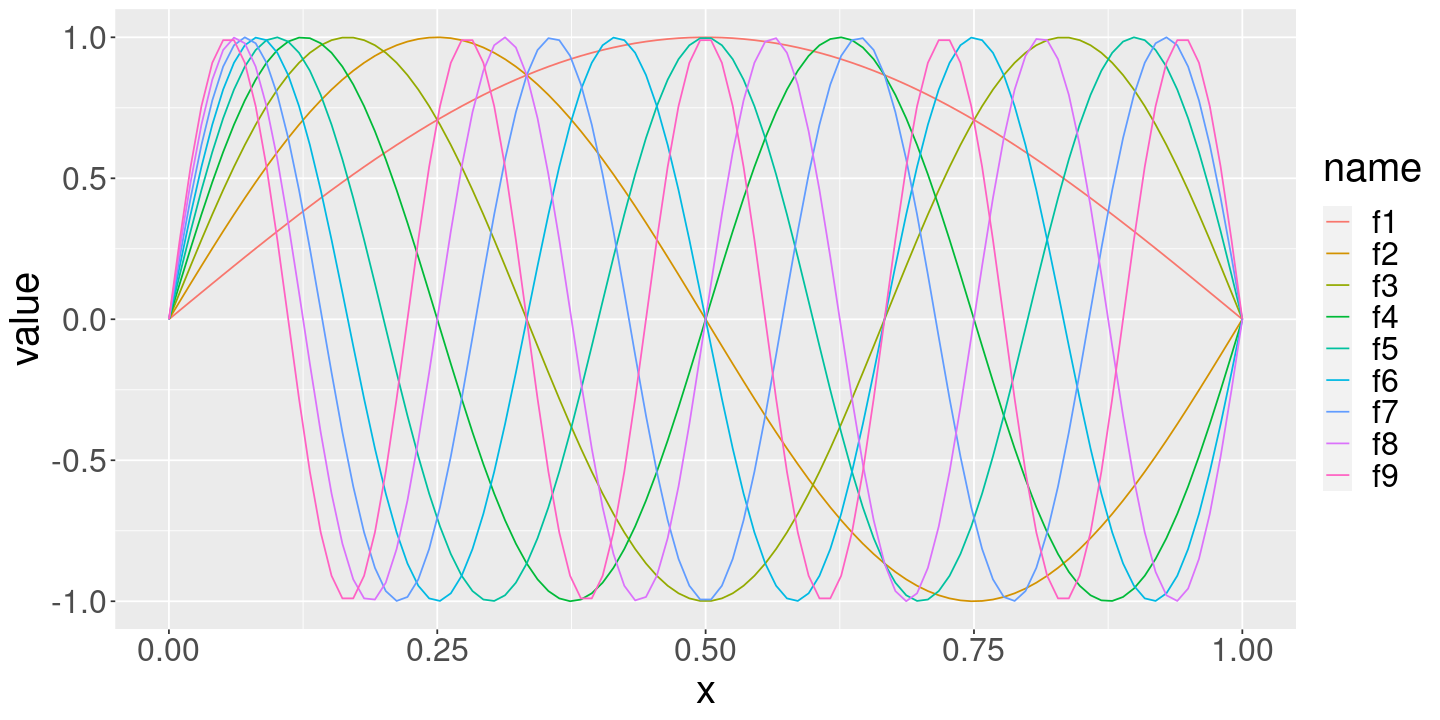
# Construct a basis of sin functions of increasing frequencypmax <-50x_grid <-seq(0, 1, length.out=100)f_mat <-EvalFeatures(x_grid, pmax)f_names <-colnames(f_mat)f_df <-data.frame(f_mat) %>%mutate(x=x_grid) %>%pivot_longer(cols=(-x)) %>%mutate(freq=as.numeric(sub("^f", "", name)))ggplot(f_df %>%filter(freq <10)) +geom_line(aes(x=x, y=value, color=name))
As we increase the number of true regressors, the functions get more wiggly, since we are including higher–frequency components. Our task is to try to figure out how wiggly our function should be by trying to estimate how many regressors to include in the model!
RegressionFormula <-function(p) {stopifnot(p <= pmax) form <-sprintf("y ~ -1 + %s", paste(f_names[1:p], collapse=" + "))return(form)}# Run a regression with the first p predictors and return the fitted values.ComputePredictions <-function(data_df, p) {stopifnot(p <= pmax) form <-RegressionFormula(p) lm_fit <-lm(formula(form), data_df)return(data.frame(y=data_df$y, ey=data_df$ey_true, y_pred=lm_fit$fitted.value, n=data_df$n))}
Now we run some simulations. For each simulation, we use a new draw of \(y\), but all the same \(x\), and all the same \(\beta\). For each dataset, we run regressions for a range of \(p\). Because we know the ground truth, we can compare the predictions to the truth.
n_obs <-500sigma_true <-0.4n_sims <-20# Draw multiple datasets with x fixed (so we can estimate bias and variance)x <-DrawData(n_obs, sigma_true, beta_true)$xdata_df_list <-lapply(1:n_sims, \(s) DrawData(n_obs, sigma_true, beta_true, x=x))err_df <-data.frame()# sanity check that all the datasets have the same xstopifnot(abs((data_df_list[[1]])$x[1] - (data_df_list[[2]])$x[1]) <1e-8)p_seq <-unique(c(1, 2, 3, 4, 5, seq(1, pmax, 5)))pb <-txtProgressBar(min=0, max=n_sims, style=3)for (sim in1:n_sims) {setTxtProgressBar(pb, sim)for (p in p_seq) { data_df <- data_df_list[[sim]] pred_df <-ComputePredictions(data_df, p) this_err_df <- pred_df %>%mutate(p=p, sim=sim) err_df <-bind_rows(err_df, this_err_df) }}close(pb)
# Estimate the expectated prediction at each datapoint (to estimate the bias)# Recall that n indexes individual datapoints, so ey_pn is an estimate of# the expected yhat for a particular x, averaged over all simulations.err_df <- err_df %>%group_by(p, n) %>%mutate(ey_pn=mean(y_pred)) %>%ungroup()# Compute the MSE and related quantitiesmse_df <- err_df %>%group_by(p) %>%mutate(pred_err=y_pred - ey, reg_err=y_pred - ey_pn,bias=ey_pn - ey) %>%summarize(mse=mean(pred_err^2), var=mean(reg_err^2), bias2=mean(bias^2), # The averaging over new data rand_err=sigma_true^2) %>%mutate(mse_check=(mse - (var + bias2)) / mse) # Sanity check -- should be zero
mse_df
A tibble: 14 × 6
p
mse
var
bias2
rand_err
mse_check
<dbl>
<dbl>
<dbl>
<dbl>
<dbl>
<dbl>
1
0.154295538
0.0002612088
0.1540343294
0.16
-1.798858e-16
2
0.071492438
0.0004750056
0.0710174322
0.16
0.000000e+00
3
0.025757448
0.0007859902
0.0249714576
0.16
0.000000e+00
4
0.024913654
0.0010975353
0.0238161190
0.16
0.000000e+00
5
0.023965436
0.0013810972
0.0225843386
0.16
0.000000e+00
6
0.013597196
0.0015696131
0.0120275824
0.16
0.000000e+00
11
0.004800805
0.0026488117
0.0021519935
0.16
-1.806701e-16
16
0.005012249
0.0039636371
0.0010486124
0.16
0.000000e+00
21
0.006122883
0.0059289516
0.0001939315
0.16
0.000000e+00
26
0.007831561
0.0075814637
0.0002500975
0.16
0.000000e+00
31
0.009338688
0.0090346805
0.0003040077
0.16
0.000000e+00
36
0.010682421
0.0103274960
0.0003549251
0.16
0.000000e+00
41
0.012504986
0.0119679744
0.0005370119
0.16
0.000000e+00
46
0.014585520
0.0139529689
0.0006325514
0.16
0.000000e+00
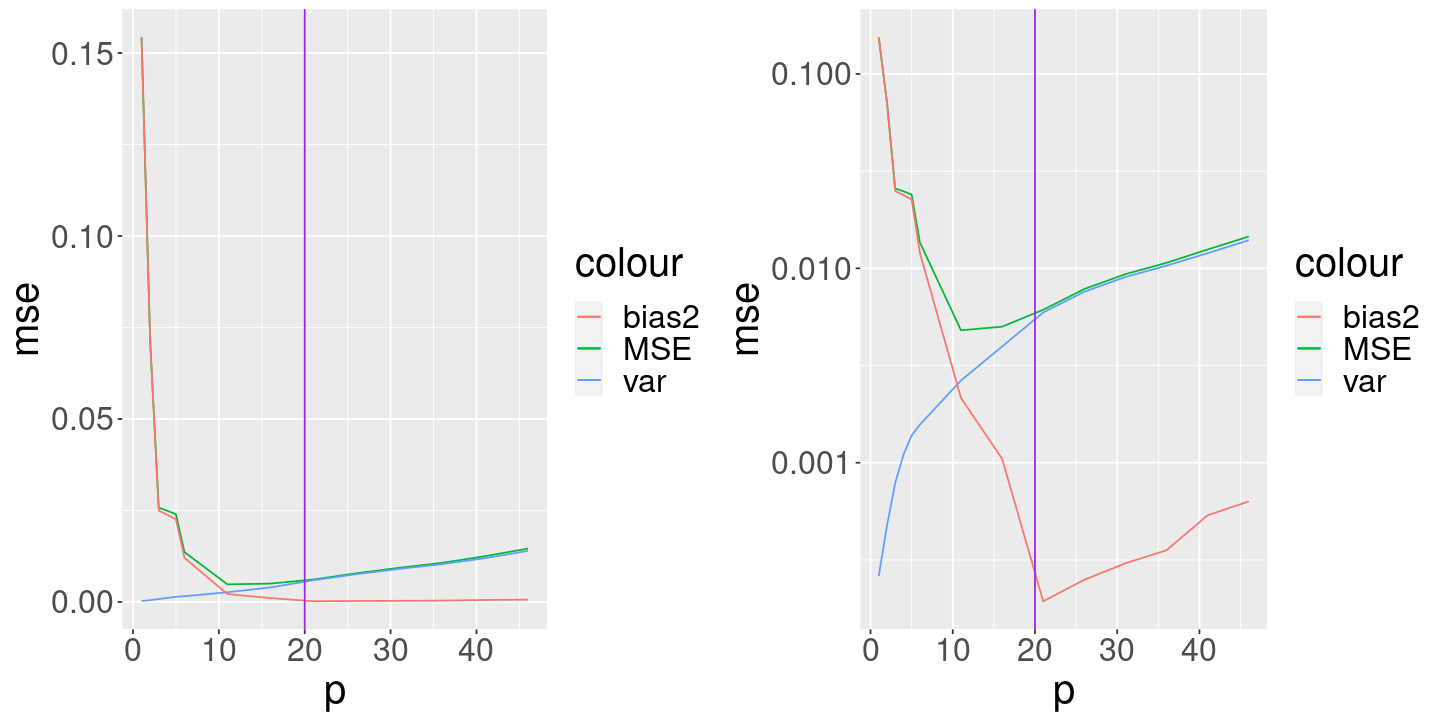
Look at how the MSE and its components vary with p, the number of regressors included in the regression.
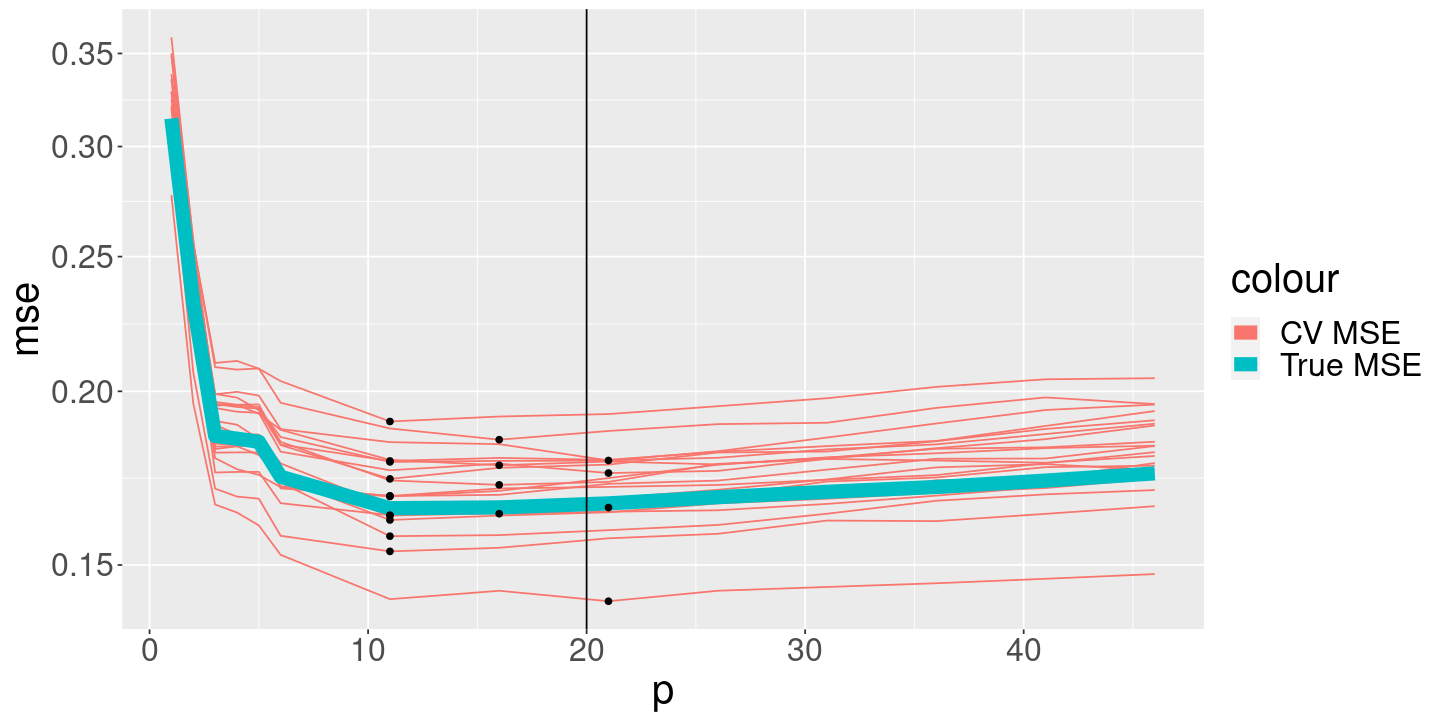
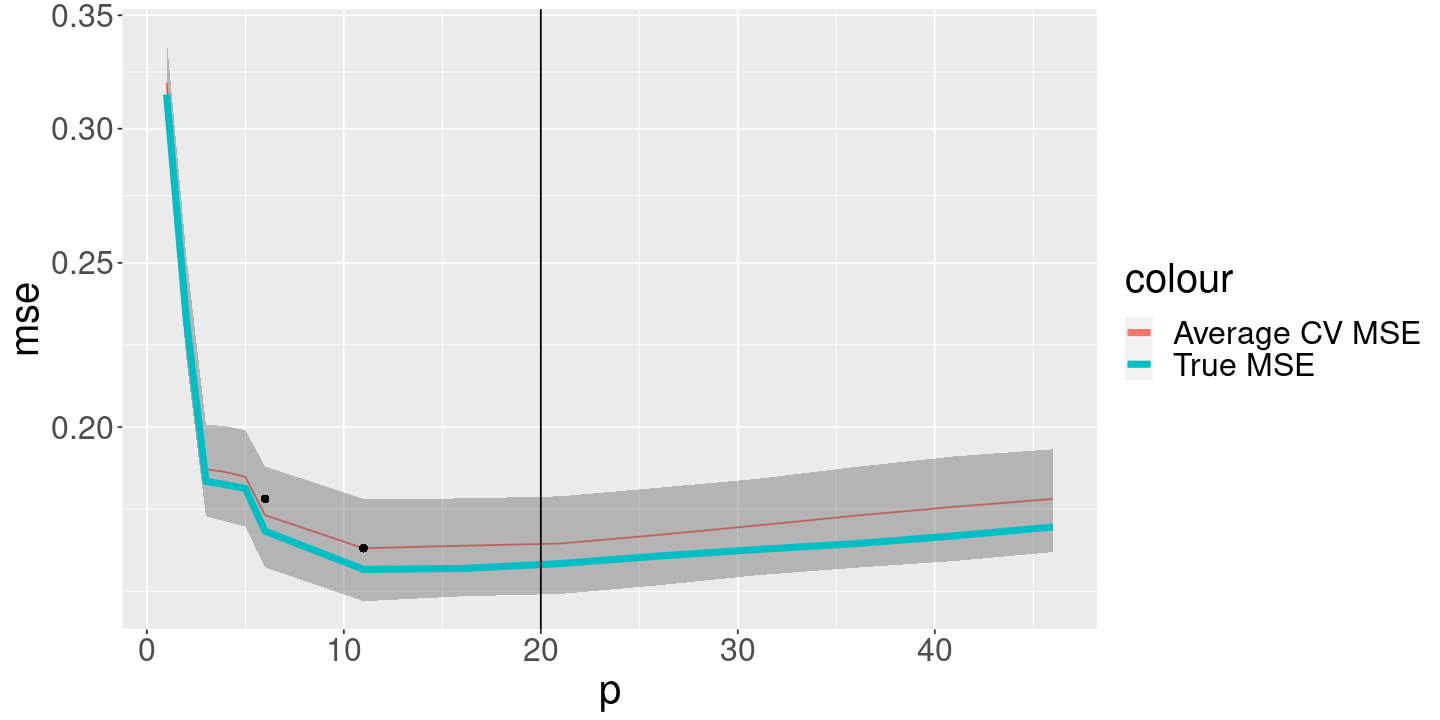
Now let’s see whether we can accurately recover the above curves using cross-validation.
We’ll use k-fold cross validation. We run the regression once for each p, and once for each simulated dataset, so we can see the variability in the CV procedure.
# For each p, and each dataset, average the mse over folds,# and identify the p for each dataset that minimizes MSE.err_cv_agg_df <- err_cv_df %>%group_by(data_ind, p) %>%summarize(mse=mean(mse), .groups="keep") %>%ungroup() %>%group_by(data_ind) %>%mutate(is_mse_min=mse <=min(mse)) # For each p, see how variable the mse is over datasets. # (In practice, you only see one dataset.)err_cv_agg_agg_df <- err_cv_agg_df %>%group_by(p) %>%summarize(mse_sd=sd(mse), mse=mean(mse), .groups="drop")min_ind <-which.min(err_cv_agg_agg_df$mse)min_mse <- err_cv_agg_agg_df$mse[min_ind]min_mse_sd <- err_cv_agg_agg_df$mse_sd[min_ind]min_p <- err_cv_agg_agg_df$p[min_ind]p_cv <- err_cv_agg_agg_df %>%filter(mse <= min_mse + min_mse_sd) %>%pull(p) %>%min()print(p_cv)
[1] 6
We see that
CV selects more variables than are correct
There is a fair amount of variability in the estimated MSE